Hadoop是一个能够对海量数据进行分布式处理的系统架构,Hadoop框架的核心是:HDFS和MapReduce,HDFS分布式文件系统为海量的数据提供了存储,MapReduce分布式处理框架为海量的数据提供了计算。
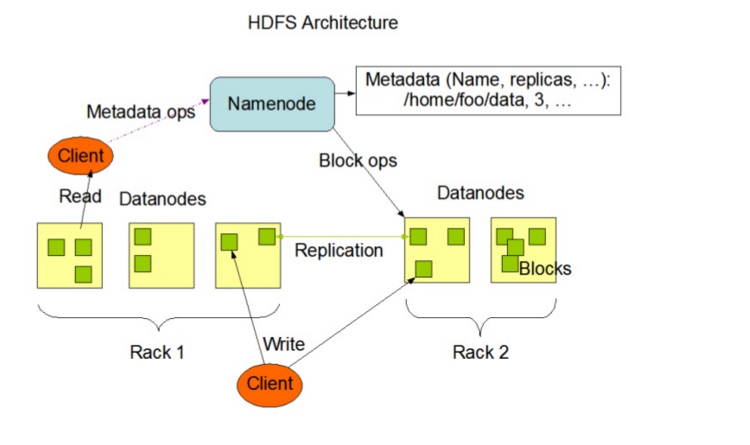
HDFS框架
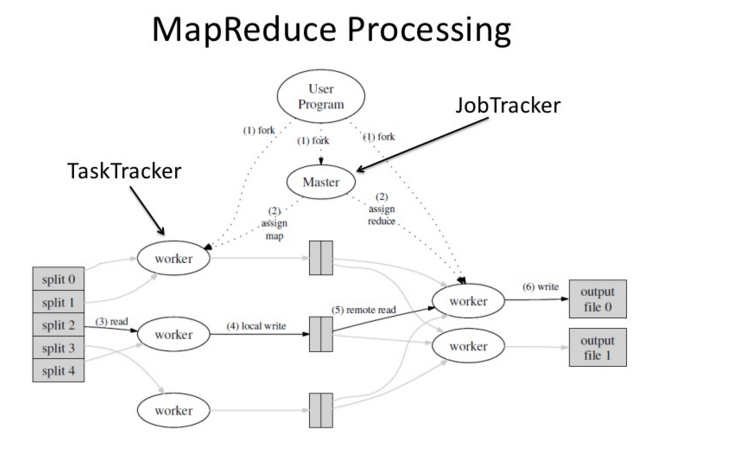
MapReduce架构
Hadoop下载安装
Hadoop下载
1 | wget http://apache.claz.org/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz |
Hadoop安装
由于Hadoop的部署需要java JDK 的支持,所以需要先安装Java JDK 参考 日志分析系统(zookeeper+flume+kafka)之实时接收数据 里边有涉及到。1
2
3cd /usr/local/
tar zxvf ./hadoop-3.2.0.tar.gz
mv ./hadoop-3.2.0 ./hadoop
环境变量设置
设置JAVA的环境变量,JAVA_HOME是JDK的位置1
2
3
4
5
6
7
8
9
10
11# 设置JAVA的环境变量,JAVA_HOME是JDK的位置
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export PATH=$PATH:$JAVA_HOME/bin
# 设置生效
source /etc/profile
# 设置Hadoop的JAVA_HOME
vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
Hadoop配置
需要配置的文件
- hadoop/etc/hadoop/hadoop-env.sh
- hadoop/etc/hadoop/yarn-env.sh
- hadoop/etc/hadoop/core-site.xml
- hadoop/etc/hadoop/hdfs-site.xml
- hadoop/etc/hadoop/mapred-site.xml
- hadoop/etc/hadoop/yarn-site.xml
core-site.xml配置
1 | <name>fs.default.name</name> |
hdfs-site.xml配置
1 | <property> |
mapred-site.xml配置
1 | <property> |
hadoop-env.sh配置
1 | # 修改文件,在末尾添加如下代码。 |
yarn-site.xml配置
1 | <property> |
yarn-env.sh配置
1 | # 修改文件,在末尾添加如下代码。 |
测试
格式换文件系统
hdfs namenode -format
启动节点
sbin/start-dfs.sh
hadoop文件管理
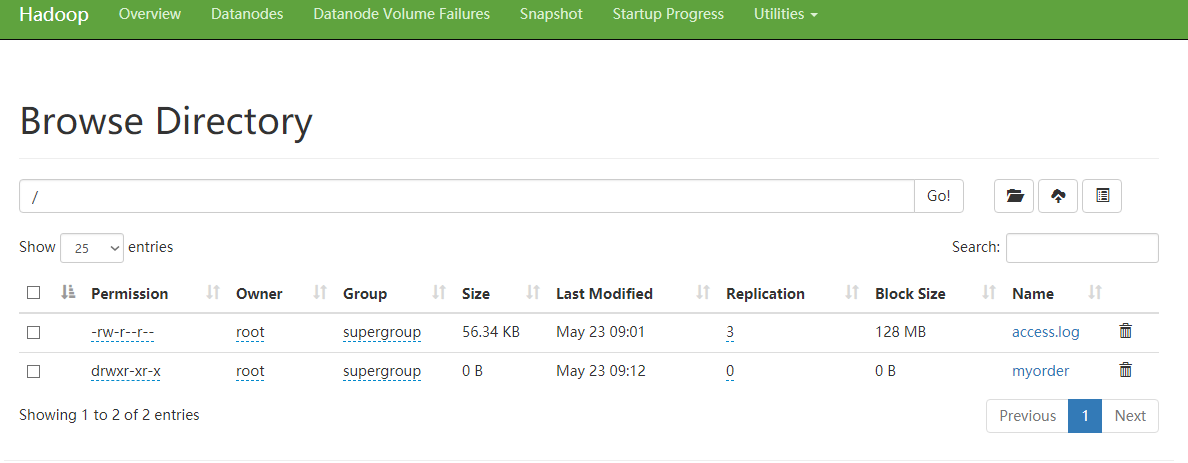
- 浏览器打开 http://10.1.1.35:50070/
hadoop 资源管理
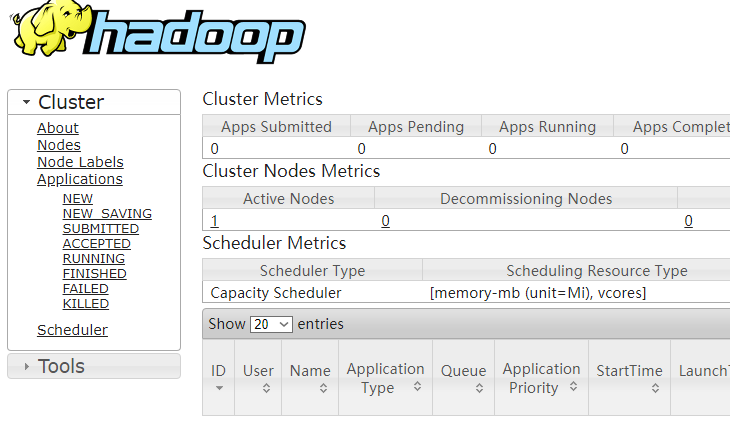
文件测试+文件wordcount
1 | # 上传 |


